Sequence-to-Sequence
; 입력 시퀀스가 인코더에 들어가면 컨텍스트 벡터 형태로 나와 디코더에 들어가고 그에 따른 디코더의 출력이 출력 시퀀스가 된다.

Encoder와 Decoder내에 각 LSTM셀이 들어있고, 이 LSTM셀은 각 입력과 출력을 한다.
예시코드를 보면서 Sequence to Sequence 모델의 구조를 이해하려고 한다.
영어로 된 문장을 한글로 번역하는 모델을 만들어 보자.
import pandas as pd
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
df= pd.read_table('/content/drive/MyDrive/Colab Notebooks/kor.txt',names=['src','tar','lic'])
del df['lic']파일경로를 보면 누가봐도 코랩환경.. 😂
3번째 열은 필요하지 않아 제거해 주었다.
df.tar= df.tar.apply(lambda x: '\t'+x+'\n') # sos: \t, eos: \n
df= df[0:3000]'tar'열이 한글로 번역된 열인데, 이 문자열마다 앞에는 ' \t ' 값을, 뒤에는 ' \n ' 값을 넣어주었다.
그리고 무료 코랩환경에서는 이 파일을 모두 돌리면 런타임 실행에서 튕기기 때문에 3000개 까지만 잘라서 넣어주었다..
돈이 좋은거시여,,,

srcVocab= set()
for line in df.src:
for c in line:
srcVocab.add(c)
tarVocab= set()
for line in df.tar:
for t in line:
tarVocab.add(t)
srcVocab= sorted(list(srcVocab))
tarVocab= sorted(list(tarVocab))영문의 한 문장마다 에서 문자 하나씩 가져와 srcVocab에 추가한다.
한글도 마찬가지로 한 문장마다에서 한 단어씩 가져와 tarVocab에 추가한다.
여기서 vocab을 set형식으로 설정하는 이유는 set구조가 중복을 포함하지 않기 때문이다. 그렇기 때문에 vacab에는 고유한 문자들 만이 들어갈 수 있다.
또, 이를 꺼내어 쓰기 쉽도록(?) 리스트 형식으로 바꾸고, 보기 좋으라고 (인지는 모르겠지만) sorted 함수를 써준다.

srcVocabSize= len(srcVocab)+1 # 67+1
tarVocabSize= len(tarVocab)+1 # 804+1
tar_to_index= dict([(w,i+1) for i, w in enumerate(tarVocab)])
src_to_index= dict([(w,i+1) for i, w in enumerate(srcVocab)])vocab의 사이즈를 설정하는데 원래 길이보다 하나 더 많게 설정하는 이유는 0번인덱스를 사용하지 않기 위해서 이다.
000_to_index변수에는 각 vocab에서 key와 value값으로 나누어 딕셔너리 형태로 저장하였다.
이 또한 1번 인덱스부터 시작하게 하기 위해, 설정값을 i+1로 둔다.


enc_input=[] # 문장별 문자의 인덱스 - 이중리스트
for line in df.src:
enc_line= [] # 한 문장에서 나오는 문자의 인덱스 모음
for c in line:
enc_line.append(src_to_index[c]) # 아스키코드값이 저장
enc_input.append(enc_line)
dec_input=[]
for line in df.tar:
dec_line= []
for c in line:
dec_line.append(tar_to_index[c]) # 아스키코드값이 저장
dec_input.append(dec_line)
dec_tar=[]
for line in df.tar:
enc_line=[]
t=0
for c in line:
if t>0: # t=0 : sos 이기때문에 포함하지 x
enc_line.append(tar_to_index[c])
t=t+1
dec_tar.append(enc_line)enc_line에는 src의 한 문장에 있는 문자에 대한 인덱스를 담아준다. 각 문장마다 리스트를 만들기 때문에 enc_input에는 모든 문장이 담기므로 이중리스트의 형태가 된다.
dec_line에도 마찬가지로 tar의 각 문장에 대해 한 문자의 인덱스를 담아줌으로 dec_input에는 모든 문장이 담긴 이중리스트의 형태를 띈다.
앞의 인코더의 입력값과 디코더의 입력값( =인코더의 출력값)을 지정해주었으니 남은건 디코더의 출력값!
dec_tar에는 dec_input 과 동일한 데이터가 이용되지만, 다른점이 있다.
그건 문장마다 문장 처음에 넣었던 ' \t '의 값을 제거한 문자열에 대해 인덱스를 부여한다는 것!
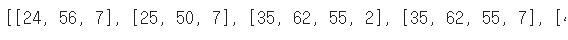


dec_tar의 리스트를 보면 dec_input에서의 맨 앞 인덱스가 빠져있는 꼴의 리스트를 볼 수 있다.
1번 인덱스의 값은 ' \t '를 가리키고 있는거다.
dec_tar에서 ' \t '의 값을 제외하는 이유는 마지막에 가서야 이해할 수 있겠지만 미리 말하자면 디코더의 출력값은 ' \t '를 가리키는 <sos> 가 나오지 않는다.
그래서 훈련시의 target값에도 넣어주지 않는것이다
max_src_len= max([len(line) for line in df.src]) # 26 = 영어 문장 최대길이
max_tar_len= max([len(line) for line in df.tar]) # 30 = 한글 문장 최대길이
# padding
enc_input= pad_sequences(enc_input, maxlen= max_src_len, padding= 'pre')
dec_input= pad_sequences(dec_input, maxlen= max_tar_len, padding= 'pre')
dec_tar= pad_sequences(dec_tar, maxlen= max_tar_len, padding= 'pre')
# one-hot-encoding
enc_input= to_categorical(enc_input)
dec_input= to_categorical(dec_input)
dec_tar= to_categorical(dec_tar)영어와 한글 문장 중에서 가장 긴 문장의 길이를 담은 변수를 만들어주었다.
이건 패딩작업을 하기 위함인데, 가장 긴 길이의 문장 길이를 알아야 모든 문장을 그만큼의 길이로 패딩해줄 수 있다.
그 이후 패딩작업한 인덱스 리스트를 원핫벡터로 만들어 준다. to_categorical 함수는 원핫벡터를 만들어주는 함수이다. 그럼 문장 내 단어마다 원핫인코딩 처리가 된다.

원핫인코딩을 하면 가장 작은 단위의 리스트는 각 문장의 단어/문자 로 나타난다. 물론 패딩작업을 거쳤기 때문에 문장 앞부분에는 패딩의 0이 들어갔음을 볼 수 있다. 파란 네모 하나가 하나의 문장을 나타내고 있다. 저렇게 그려놓으면 보기 편한가 !
enc_input.shape # (3000, 26, 68)= (데이터 개수, 입력단어의 개수= lstm셀의 개수, 문자의 종류)
dec_input.shape # (3000, 30, 805)=(데이터 개수, 디코더의 최대 길이, 차원)
dec_tar.shape # (3000, 30, 805)=(, , 차원)뭐 다 조금씩 다르게 써놨지만 자리마다 같은 의미이다.
enc나 dec의 같은 자리의 수치가 의미하는 의미는 같다는 뜻....
Encoder ( 인코더 )
from tensorflow.keras.layers import Embedding, Dense, LSTM, Input
from tensorflow.keras.models import Model
import numpy as np
# Encoder
enc_inputs=Input(shape=(None, srcVocabSize))
enc_lstm= LSTM(units= 256, return_state= True)
enc_outputs, stateH, stateC= enc_lstm(enc_inputs)
enc_states =[stateH, stateC] # context vector인코더에 넣는 입력문장의 개수는 굳이 정하지 않아도 자동으로 알아서 조절하여 들어가도록 None값을 넣었다. 사실은 None 자리에 26이 들어가야 맞는거겠지?
음 그러니까 다시 표현하자면, 3000개의 문장을 하나씩 넣는건데 문장의 shape을 넣어줘야 하기 때문에 위의 shape문에서 확인한 크기에서 3000을 제외한 크기를 넣어준다고 생각하면 된다.
LSTM셀을 선언하는데 units은 임의의 값이고, return_state는 다음 LSTM셀로 전달할것인지를 나타낸다.
lstm의 반환값으로 인코더의 출력값과 stateH, stateC를 출력한다.
stateH에는 hidden state( 은닉 상태 정보 )를, stateC에는 cell state( 셀 상태 정보 )를 담는다. 이 정보들이 중요한 역할을 한다.
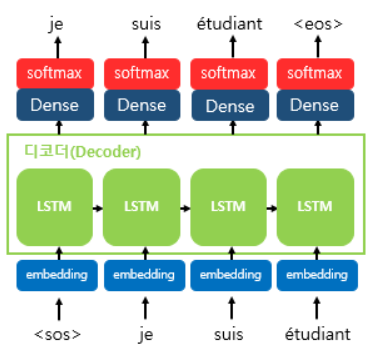
Decoder ( 디코더 )
# Decoder
dec_inputs=Input(shape=(None, tarVocabSize))
dec_lstm= LSTM(units= 256, return_state= True, return_sequences= True)
dec_outputs, _, _= dec_lstm(dec_inputs, initial_state= enc_states) # 전달 enc_states⭐디코더는 디코더의 입력값 모양만 바꿔주고 LSTM셀만 다시 선언한다.
lstm의 반환값으로 디코더의 출력값만 받는데, 뒤 두가지 인수를 비워놓는 이유는 사용하지 않기 때문이다.
사실 저 두 빈자리는 인코더에서와 똑같이 stateH와 stateC인데 디코더에서 출력되는 state값은 필요하지 않기 때문에 비워두고 버리는 값이 되었다. 대신 디코더 lstm의 파라미터로 받는 state값은 인코더에서 출력된 state값을 넣어준다.
enc_states 값을 전달해 주는게 중요하다⭐
인코더 - 정보 -> 디코더
dec_layer= Dense(tarVocabSize, activation= 'softmax')
dec_outputs= dec_layer(dec_outputs)
model= Model([enc_inputs, dec_inputs], dec_outputs) # functional API 사용
model.compile(optimizer= 'rmsprop', loss= 'categorical_crossentropy')
model.fit(x= [enc_input, dec_input], y= dec_tar, batch_size=64, epochs=10,
validation_split= 0.2)디코더에서 나온 출력값을 dense layer에 넣어 활성화함수를 적용시킨다. 활성화함수는 softmax함수로 하였고, 이 layer층을 통과한 출력값을 최종출력값으로 한다.
> test데이터를 돌려볼수는 없었지만 구조를 이해하기에는 좋은 수업이었다. :)
다만, 꼭 혼자서 생각해봐야하는 모델구조였다..
**Seq2Seq의 문제점**
- 컨텍스트 벡터의 크기가 정해져 있어서 매우 긴 문장의 경우 정보손실의 우려가 큼
- vanishing gradient : 기울기 소실
'Natural Language Processing' 카테고리의 다른 글
| [ChatGPT] Prompt Engineering (0) | 2023.08.03 |
|---|---|
| [NLP] Transformer 트랜스포머 모델 (0) | 2023.08.01 |
| [NLP] Word2Vector (0) | 2023.08.01 |
| [NLP] Transfer Learning 전이학습 (0) | 2023.07.31 |
| [NLP] 정규표현식 (0) | 2023.07.25 |



