시퀀스 배열로 다루는 순환 신경망 (RNN)
이전까지는 단어와 단어 간의 관계나 연관으로 임베딩값이 결정되었다. (NN)
하지만 이는 문장 전체의 의미를 이해할 수 없다.
이를 해결하기 위해 '순환신경망' 방법이 고안됨 ❗
RNN (Recurrent Neural Network, 순환신경망)
- 순환 신경망은 여러개의 데이터가 순서대로 입력되었을 때, 앞서 입력받은 데이터를 잠시 기억해 놓는 방법
- 기억된 데이터가 얼마나 중요한지 판단하여 별도의 가중치를 부여
- 모든 입력 값에 이 작업을 순서대로 실행하므로 다음 층으로 넘어가기 전에 같은 층을 맴도는 것 처럼 보임 → 순환신경망

예를 들어, ' 오늘 주가가 몇이야? ' 라고 묻는다고 가정해보면

토큰 단위로 모델에 입력된다고 했을 때, 앞에 들어가는 입력에 따라 뒤로 전달되는 값이 달라지게 된다.
입력 1에 들어가는 '오늘' 이라는 단어대신 '어제' 라는 단어가 들어갔다면 출력이 달라지게 될 것이다.

따라서, 앞의 입력이 뒤의 결과에 영향을 미친다는 것을 알 수 있다.
> 그러나 한 층 안에서 반복을 많이 해야 하는 RNN의 특성상 일반 신경망보다 기울기 소실문제가 더 많이 발생하고, 이를 해결하기 어렵다는 단점이 있다.
> 즉, 출력에서 멀리 떨어진 아주 이전에 들어온 입력은 기억하지 못할 수 있다.
LSTM (Long Short Term Memory) 알고리즘
- RNN의 결과를 더욱 개선하기 위해 LSTM을 함께 사용하는 방법이 현재 가장 널리 이용되고 있다.
- LSTM은 위와 같은 기울기 소실 문제를 보완하기 위한 방법이다.
- 반복되기 직전에 기억된 값을 다음 층으로 넘길지 안 넘길지 관리하는 단계를 하나 더 추가한다.

RNN이 기존의 뉴럴 네트워크와 다른 점은 '기억'을 갖고 있다는 것이다. (이는 나중에 hidden state라 불린다.)
새로운 입력이 들어올 때마다 네트워크는 '기억'을 조금씩 수정하고, 모든 입력이 끝나면 남아있는 '기억' 은 시퀀스 전체를 요약하는 정보가 된다. ( 중요한 데이터는 기억하고, 중요하지 않은 데이터는 버림)
따라서 순환신경망은 이런 반복을 통해 긴 시퀀스라도 처리가 가능하게 한다.

가장 아래 빨간색이 입력, 노란색이 기억, 초록색이 출력 이라고 할 때,
첫번째 입력에 따라 첫번째 기억이 만들어지고
두번째 입력이 들어오면 기존의 기억과 새로운 입력에 따라 두번째 기억이 만들어진다.
이와 같이, 기억은 새로운 입력과 기존의 기억에 따라 업데이트 되어 전달된다.
각 기억은 그때까지의 입력을 요약해서 가지고 있는 정보가 된다.
마지막에 가진 기억 즉, 지금까지의 요약된 정보를 바탕으로 출력을 생성한다.
RNN방식

- 단일 입력 단일 출력 (one to one)
: 고정크기의 입력과 출력, 순환적인 부분이 없기 때문에 RNN이라고 볼 수 없다. - 단일 입력 다수 출력 (one to many)
ex) Image Captioning : 하나의 이미지에 대해 설명, 이미지 내의 여러가지를 텍스트로 출력 - 다수 입력 단일 출력 (many to one)
ex) Sentiment Classification : 문장을 입력하여 이에 대한 긍/부정을 출력 - 다수 입력 다수 출력 (many to many)
ex) Translation Machine : 번역모델, 한글로 텍스트를 입력하면 영어로 번역하여 출력한다. 이때 해당 문장을 모두 학습한 후에 그 문장 자체를 번역하는 것이 더 정확한 번역이 될 수 있기에, 입력이 끝나면 출력이 이루어진다.
ex) 영상데이터 내의 프레임마다 어떤 장면인지 인지하여 출력한다. 한 입력마다 출력이 계속해서 일어난다.
혹은
문장에서 다음에 나올 단어를 계속해서 예측한다. 문장이 이어짐에 따라 그 다음 단어를 예측.
RNN의 구조
앞서 설명했던, 이전 상태로부터 전달된 기억을 히든 스테이트(hidden state)라고 한다.
현재 타임스텝의 hidden state는 새로운 입력과 이전 히든 스테이트의 영향을 받아 매번 갱신된다.
다른 신경망(NN)과 마찬가지로 RNN역시 경사하강법(Gradient Descent)과 오차 역전파(Backpropagation)를 이용해 학습한다. 정확하게는 시간흐름에 따른 작업을 하기 때문에 역전파를 확장한 BPTT(Back-Propagation Through Time)을 사용해 학습한다.

RNN구조 그림을 보면 순환하는 곳에 A라고 쓰여있는 곳에서 활성화함수(Activation Function)이 적용된다.
보통 RNN의 활성화 함수로는 tanh 함수를 사용한다.

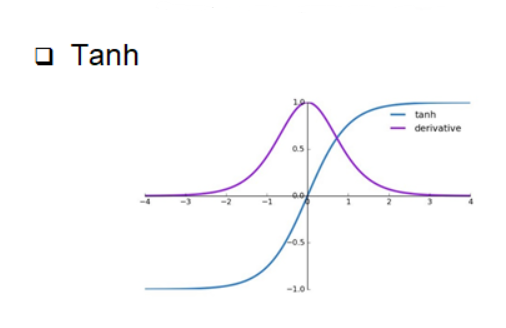
위 두 함수를 비교해 보면 sigmoid함수는 0에서 1사이의 값을 가지고, tanh 함수는 -1에서 1 사이의 값을 가지는 것을 확인할 수 있다. 각 함수의 미분함수를 보면 sigmoid에 비해 tanh함수의 미분최대값이 더 큼을 알 수 있다.
따라서 sigmoid에 비해 tanh함수가 기울기 소실(Gradient Vanishing) 문제에 더 유리하다고 할 수 있다.

또한, relu함수의 경우 출력으로 0보다 크면 그대로 값을 내보내게 되어, 속도와 학습률이 증가하지만
RNN계열은 계속해서 반복순환하는 성질이 있으므로 레이어가 반복하면서 값이 발산할 수 있다.
> 따라서 RNN의 활성화 함수로는 tanh 함수를 사용한다.
'Natural Language Processing' 카테고리의 다른 글
| [Goorm] 딥러닝을 이용한 자연어 처리 6 (LSTM과 CNN으로 IMDB 사용하기) (0) | 2024.07.07 |
|---|---|
| [Goorm] 딥리닝을 이용한 자연어 처리 5 (LSTM 이용) (0) | 2024.07.06 |
| [Goorm] 딥러닝을 이용한 자연어 처리 3 (IMDB + GloVe 이용) (1) | 2024.07.05 |
| [Goorm] 딥러닝을 이용한 자연어 처리 2 (IMDB 이용) (0) | 2024.07.05 |
| [Goorm] 딥러닝을 이용한 자연어 처리 1 (토큰화 & 임베딩) (0) | 2024.06.23 |


