LSTM을 이용한 로이터 뉴스 카테고리 분류하기
: 입력된 문장의 의미를 파악하는 것은 단어간의 관계를 파악한다기 보다 모든 단어를 종합하여 하나의 카테고리로 분류하는 작업이라고 할 수 있다.
1. 데이터 로드
import numpy
import tensorflow as tf
from tensorflow.keras.datasets import reuters
# seed값 설정
seed= 0
numpy.random.seed(seed)
tf.random.set_seed(seed)
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=1000, test_split=0.2)
# 데이터 확인하기
category= numpy.max(y_train)+1
print(category, '카테고리') # 46 카테고리
print(len(x_train), '학습용 뉴스 기사') # 8982 학습용 뉴스 기사
print(len(x_test), '테스트용 뉴스 기사') # 2246 테스트용 뉴스 기사
print(x_train[0]) # [1, 2, 2, 8, 43, 10, 447, ... ]
word_to_index= reuters.get_word_index()
index_to_word= {index:word for word, index in word_to_index.items()}- word_to_index : 단어-인덱스 가 쌍으로 연결된 딕셔너리
- ex) the: 1, of: 2, to:3 등 사용 빈도가 높은 단어순으로 index가 정의됨
- 가져온 데이터는 인덱스로 이루어진 문장형태
- 각 인덱스를 해당 word로 바꿔서 문장을 확인해 보면, 정수 인코딩 전 전처리가 되어 제대로 된 문장이 나오지는 않음
- 빈도수를 기준으로 상위 1000개의 단어만 가져왔으므로 가져오지 못한 단어들로 인해 불완전한 문장이 되어버림
- ex) the of of mln loss for plc said at only ended said of could 1 traders now april ...
2. 데이터 전처리
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.utils import to_categorical
# 데이터 전처리
x_train= sequence.pad_sequences(x_train, maxlen=100)
x_test= sequence.pad_sequences(x_test, maxlen=100)
y_train= to_categorical(y_train)
y_test= to_categorical(y_test)- to_categorical() : 정수형(integer) 클래스 레이블(label)을 원-핫 인코딩(one-hot encoding) 벡터로 변환하는 함수
(단, 음수값을 클래스 레이블로 가지고 있으면 오류가 나기 때문에 to_categorical 함수를 사용하기 전에 클래스 레이블을 확인하고 음수 값이 없는지 확인해야 함.)- to_categorical( 클래스 데이터, 클래스의 개수) 형식으로 지정
3. 모델 설정
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, LSTM
# 모델의 설정
model= Sequential()
model.add(Embedding(1000, 100)) # 1000개의 고유 단어를 각 100차원으로 변환
model.add(LSTM(100, activation='tanh')) # 마지막 출력층에 대해 100차원(하나의 리스트 (1,100))으로 출력
model.add(Dense(46, activation='softmax')) # 46개의 클래스에 대해 확률값을 출력
# 모델의 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델의 실행
history= model.fit(x_train, y_train, epochs=30, batch_size=100, validation_data= (x_test, y_test))- Embedding (a,b) : a개의 고유 단어들을 b개의 차원으로 임베딩 변환.
- 각 단어마다 b개의 가중치로 이루어짐
- LSTM (c, return_sequences, activation) : c개의 차원으로 정보벡터를 출력
- return_sequences가 True 일 경우, 각 타임스텝마다 c차원의 벡터를 출력하고 ( (max_len * c) 차원이 됨)
return_sequences가 False 일 경우, 마지막 타임스텝의 정보만을 c차원으로 출력 ( (1*c) 차원 출력)
- return_sequences가 True 일 경우, 각 타임스텝마다 c차원의 벡터를 출력하고 ( (max_len * c) 차원이 됨)
> RNN은 학습 데이터의 길이가 길어질수록 더 이전의 과거 정보를 현재에 전달하기 힘들기 때문에 학습이 쉽지 않다. 역전파 도중, 과거로 올라가면 올라갈수록 gradient(기울기) 값이 소실(0으로 수렴)되는 문제를 vanishing gradient문제 라고 한다. RNN의 기울기 소실로 인한 장기의존성 문제를 해결하기 위해 LSTM이 고안되었다.
> LSTM의 활성화 함수로 tanh함수를 사용하는 이유는 이전 포스팅을 참고하길 ❗
[Goorm] 딥러닝을 이용한 자연어 처리 4 (RNN & LSTM)
시퀀스 배열로 다루는 순환 신경망 (RNN) 이전까지는 단어와 단어 간의 관계나 연관으로 임베딩값이 결정되었다. (NN)하지만 이는 문장 전체의 의미를 이해할 수 없다.이를 해결하기 위해 '순환
data-yun.tistory.com
- Dense( ) : 최종 출력 레이어
- activation : 이진 분류의 경우 sigmoid, 다중 분류의 경우 softmax를 사용한다.
- compile( )
- loss - binary_crossentropy : 이진 분류 시, 0 혹은 1로 출력
categorical_crossentropy : 다중 분류 시, 원핫 인코딩 형태의 리스트로 반환 (ex. [1,0,0], [0,1,0], [0,0,1] )
sparse_categorical_crossentropy : 다중 분류 시, 클래스의 인덱스로 반환 (ex. 3, 5 )
- loss - binary_crossentropy : 이진 분류 시, 0 혹은 1로 출력
4. 테스트
# 테스트 정확도 출력
print("\n 테스트 정확도: %.4f" % (model.evaluate(x_test, y_test)[1]))
# 테스트 셋의 오차
y_vloss= history.history['val_loss']
# 학습셋의 오차
y_loss= history.history['loss']> 테스트 정확도: 0.6990
5. 결과 그래프
import matplotlib.pyplot as plt
# 그래프로 표현
x_len= numpy.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker= '.', c= 'red', label= 'Testset_loss')
plt.plot(x_len, y_loss, marker= '.', c= 'blue', label= 'Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc= 'upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()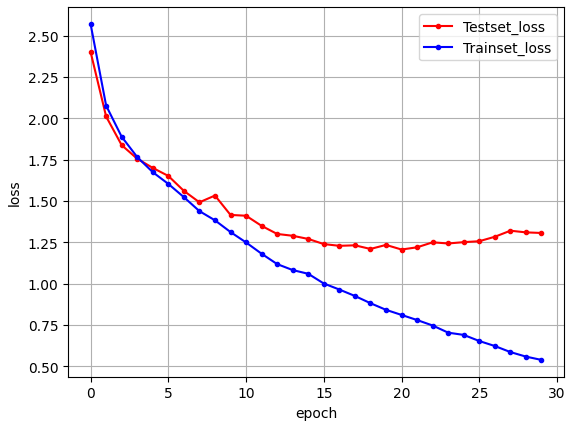
> 성능이 좋아보이지 않는다.
6. 데이터 확인
# 각 카테고리의 기사 수 확인
import numpy as np
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000, test_split= 0.2)
category= np.max(train_labels)+1
print('카테고리수 : ',category)
uniq, count= np.unique(train_labels, return_counts= True)
category_counts= dict(zip(uniq, count))
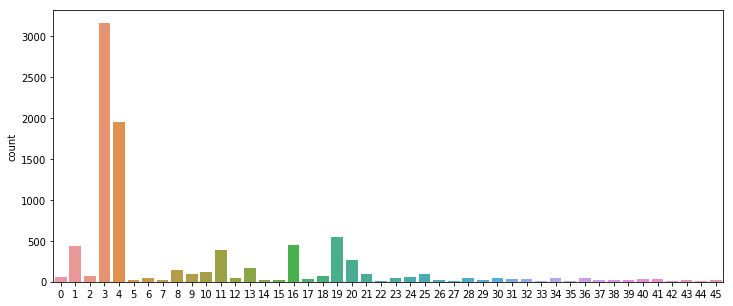
print('각 카테고리별 기사수 : ',category_counts)카테고리수 : 46
각 카테고리별 기사수 : {0: 55, 1: 432, 2: 74, 3: 3159, 4: 1949, 5: 17, 6: 48, 7: 16, 8: 139, 9: 101, 10: 124, 11: 390, 12: 49, 13: 172, 14: 26, 15: 20, 16: 444, 17: 39, 18: 66, 19: 549, 20: 269, 21: 100, 22: 15, 23: 41, 24: 62, 25: 92, 26: 24, 27: 15, 28: 48, 29: 19, 30: 45, 31: 39, 32: 32, 33: 11, 34: 50, 35: 10, 36: 49, 37: 19, 38: 19, 39: 24, 40: 36, 41: 30, 42: 13, 43: 21, 44: 12, 45: 18}
> 각 카테고리는 최소 10개에서 최대 3159개 까지 불균형한 데이터를 가지고 있었다.
그래프로 확인해보면
import seaborn as sns
fig, axe= plt.subplots(ncols= 1)
fig.set_size_inches(12,5)
sns.countplot(train_labels)
7. 결과 분석
① 위 그래프에서 볼 수 있듯이 클래스 별로 분포 비율의 차이가 크다
→ 전처리의 필요성이 보임 ❗
import matplotlib.pyplot as plt
print('뉴스 기사 최대 길이: ', max(len(l) for l in train_data))
print('뉴스 기사 평균 길이: ', sum(map(len, train_data))/len(train_data))
# 2376
# 145.5398
plt.hist([len(s) for s in train_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show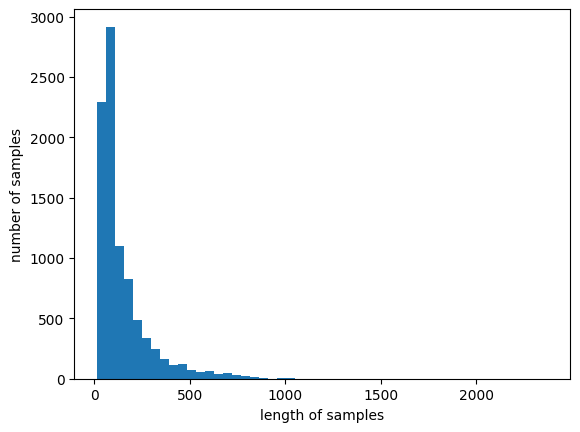
② 각 텍스트(뉴스 기사)의 길이 차이가 크다. 패딩을 200으로 하면 어떨까 ❗
③ train set과 test set의 그래프 비교를 통해 과적합이 우려됨
→ 따라서 dropout이나 earlystopping과 같은 과적합 방지 알고리즘을 추가해보면 어떨까 ❗
'Natural Language Processing' 카테고리의 다른 글
| [Goorm] 딥러닝을 이용한 자연어 처리 7 ( Seq2Seq 와 인코더/디코더) (1) | 2024.07.09 |
|---|---|
| [Goorm] 딥러닝을 이용한 자연어 처리 6 (LSTM과 CNN으로 IMDB 사용하기) (0) | 2024.07.07 |
| [Goorm] 딥러닝을 이용한 자연어 처리 4 (RNN & LSTM) (4) | 2024.07.05 |
| [Goorm] 딥러닝을 이용한 자연어 처리 3 (IMDB + GloVe 이용) (1) | 2024.07.05 |
| [Goorm] 딥러닝을 이용한 자연어 처리 2 (IMDB 이용) (0) | 2024.07.05 |



