728x90
반응형
RNN: 순환신경망



하이퍼볼릭탄젠트 > 손실이 적음
분류 > 소프트맥스
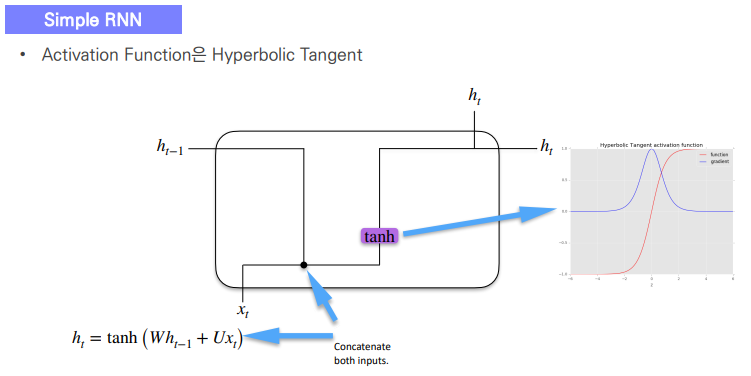
tanh대신 relu사용 상관x
But 시퀀스가 길수록 많은 손실을 야기한다. > tanh 사용
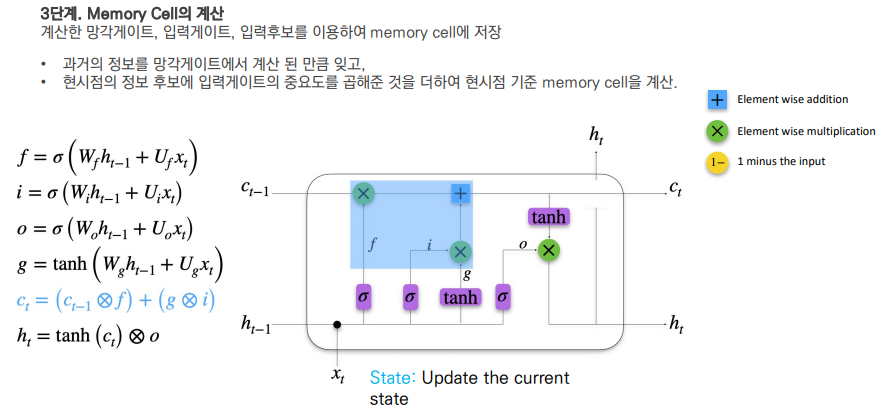
LSTM 모델
>>링크



All gates use the same inputs and activation functions, but different weights
Output gate: How much of the previous output should contribute?

GRU
Time Series
dbtkeh->
딥러닝 시 추세, 계절성 등을 고려하지 않아도 ㄷ된다
(복잡한 패턴을 포착)

728x90
반응형
'Deep Learning' 카테고리의 다른 글
| [DL] 신경망 (Neural Network) (수정중) (0) | 2023.08.14 |
|---|---|
| [DL] AutoGrad (수정중) (0) | 2023.08.13 |
| [DL] CNN_2 (0) | 2023.08.10 |
| [DL] CNN (0) | 2023.08.09 |
| [DL] 딥러닝 개요_2 (0) | 2023.08.08 |


